

Last week from the June 22th to 26th, our very own data engineers from SmartDigital, Matthias Harder, Jiawei Cui and Michael Schaidnagel, attended the digital Spark + AI Summit 2020. For the first time the event was hosted completely online by DataBricks, the creators of Apache Spark. Spark is a unified analytics engine that enables large-scale data processing. The event was comprised of two days of training courses and three days of interactive sessions, panel discussion groups, and technical deep dives from international industry leading experts. For us, the conference was a one-stop-shop for two fields that are part of our DNA, big data and data science. Spark not only powers our inhouse data lake solution, but Spark also prepares our data and trains our machine learning (ML) models.
Here is a breakdown of our main takeaways of the conference:
Spark 3.0
The first day was kicked-off by the introduction of Spark 3.0. One of the main highlights of this new version, among others (e.g. dynamic partition pruning, query compile speedups, and optimizer hints), is the Adaptive Query Execution (AQE) that allows out of the box performance speeds-ups while querying Spark clusters. AQE is able to change the execution plan at run time and the number of reducers automatically. This is especially helpful when calculating joins. We at Smart Digital hope that we can streamline some of our preprocessing steps and directly join our tables.
With the advent of AQE, we expect to see a paradigm shift in the big data industry away from normalizing tables to a more denormalized database-like form with many smaller dimension tables and joins. This will surely increase the adoption rate of Spark based systems and also fits perfectly with the other main topic of the conference: the Delta Lake.
Delta Lake
Data Lakes are historically built on large amounts of binary files; such projects have historically struggled with modifications of existing data, poor real-time performance, and the so called ‘too many files’ problem. Specifically, modifications and operations on those binary files are problematic because the rewriting of the files creates access issues. The Delta Lake layer solves the access issue by creating a previous version of the data to accompany the native binary files, along with saving and handling meta-data on the files. Thus, the Delta Lake makes every operation transactional and guarantees the ACID´ness (atomicity, consistency, isolation, durability) of the database. In simpler words: if one operation is updating a value in a table and another operation wants to read that values, the second operation has to wait until the first operation has finished updating.
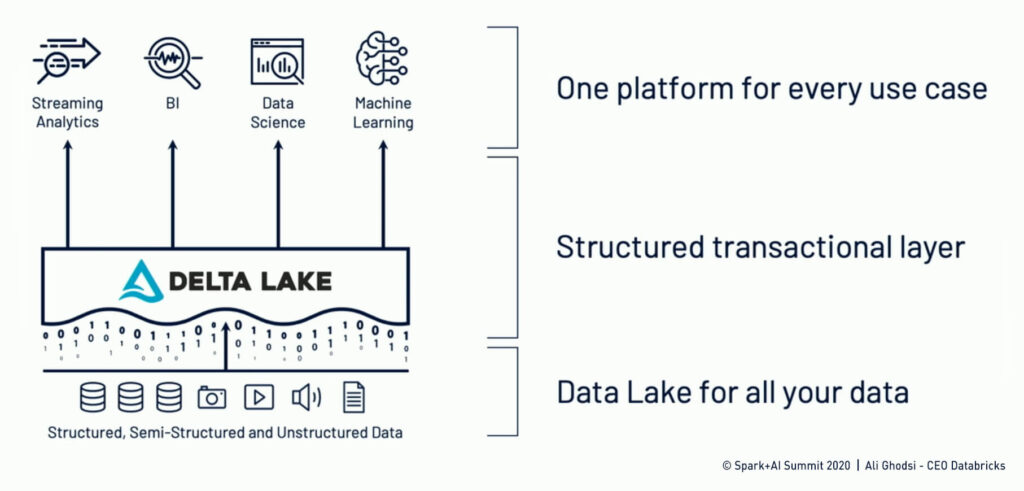 Ali Ghodsi – Intro to Lakehouse, Delta Lake
Ali Ghodsi – Intro to Lakehouse, Delta Lake
Developments in Data Science Sphere
Aside from the big data architecture, the Data Science aspect of the conference was very interesting for us. Around 90% of currently existing data was generated in the last 2 years; data growth is and has been in recent years exponential. The only way to efficiently leverage big data is through AI and ML. Developing applications and frameworks of AI and ML that allow enterprises to retrieve, digest, analyze the data, and then turn that data into tangible solutions is more important than ever. We were therefore happy to see, in several sessions, the progress made by technologies like ML flow and Kubeflow. These emerging technologies guide the process from data preparation to proper model training, pipelines required for high performing accurate models. The conference also helped us decide which technology to adopt in the future for our in-house data science workbench. We also found the training and sessions about Reinforcement Learning very exciting, as we see that as an area of ML with very high potential in the future.
The conference was a very rich learning experience for our team, and we are looking forward to putting all the new features and learnings into practice!
Photo: Paul Smith | Unsplash